micro:bit atoA(小文字を大文字に変換する)プログラム(4) : アルゴリズム
この記事で説明すること
以下の記事の続きです。今まではこの atoAのプログラムに必要な関数や条件分岐、繰り返しについて学びました。今回の記事ではこれらのテクニックを使い、どのようにこのプログラムを進めていくかを記載します。今回がこのプログラムの最終章になります!
早速ですが、このプログラムのアルゴリズムを考えていきたいと思います。
アルゴリズムとは
ある事を実現するためのプログラムにおいて、そのある事を実現するための手順、やり方のことをアルゴリズムと呼びます。1+1が何かを求めるプログラムは1+2-1としても良いのです。このアルゴリズムが、プログラムの良し悪しを決めるといっても過言ではありません。皆さんが何かを実現しようと考えている時、その手順を頭の中で想像しますよね。その手順がアルゴリズムです。
atoAのプログラムを考えていく
このプログラムにおける重要なポイントは 'a’という文字列を受信したら"A"に変換する、という部分です。これをどのような手段で実現するか、これが重要です。前回の記事でも少し記載しましたが、条件分岐(if文)で全てのパターンを記述するのも正しいやり方です。それ以外に、どのような方法があるでしょうか?
以前、こちらの記事でシリアル通信の文字列データは、ASCIIコードで送られています、と書きました。
今回はこのASCIIコードを使い、Teratermで入力された文字の判定を行っていきます。と言っても、どうやって実現していくのかサッパリ手が付けられないことかと思います。まず、スタートは以下の形で、ここから"Convert_a_to_A"の関数の中身のみを変更していきます。

まず、わかりやすいところから説明すると、"a"という文字列はASCIIコードで0x61(十進数で97)のデータとして送受信が行われます。一方で大文字に変換後の"A"はASCIIコードで0x41(65)のデータとして送受信が行われます。
同じように 小文字の b は 0x62(98)、大文字の B は 0x42(66)
小文字の c は 0x63(99)、大文字の C は 0x43(67)
という具合なので、文字列をASCIIコードで比較し、32を引いた後にASCIIコードに変換出来れば変換が出来る、ということになります。整理すると、
① 文字列データが a-zのASCIIコード(0x61 – 0x7a) かどうかを判定する
② a-z のASCIIコードであった場合は 32 を引いた値を計算する
③ ②で得られた値をASCIIコードに従って文字列に変換する
と言う流れになります。
さて、ここからは実際にプログラムを実装していきます。細かいパーツの説明は行いませんので、もしわからないことがありましたら、コメントでも良いのでお問合せ下さい。
まず①のプログラムを記述します。本当は文字列のASCIIコードがわかるパーツが用意されていれば良かったのですが、残念ながら2020/04/30時点でMakecodeにこのようなパーツが用意されていないので、ASCIIコードを97から1ずつ増やしながらアルファベットの数(26)だけ確認していきます。
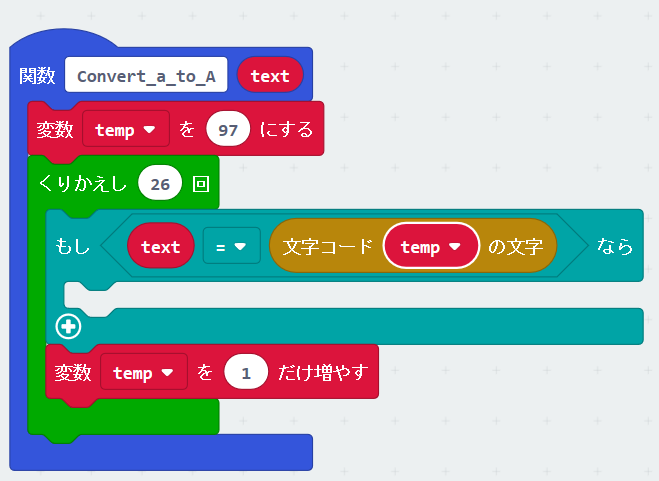
これで受信した文字列がa – zであった時のみこの条件分岐に合致しますので、次は②と③のプログラムを作っていきます。文字を文字コードに変換するパーツは用意されていませんが、文字コードから文字に変換するパーツは用意されていますので、以下のようにまず③のプログラムを作成します。
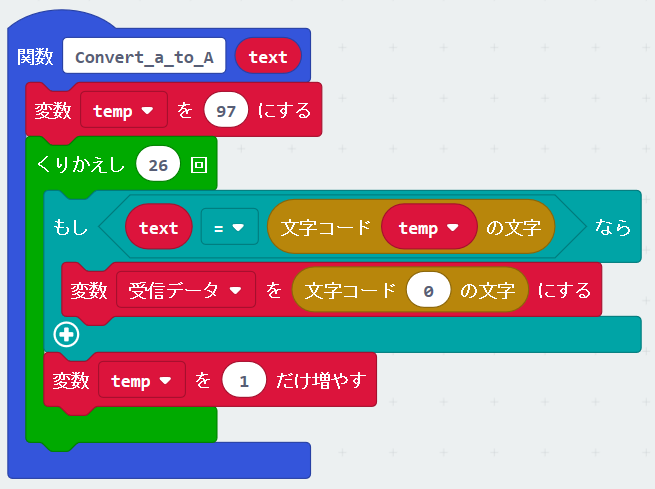
最後に変数 “temp" に入った受信した文字のASCIIコードの番号から、32を引いた値を文字に変換するように修正します。
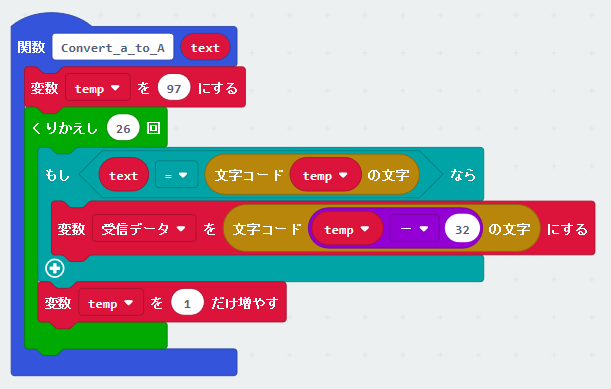
全体でみると…
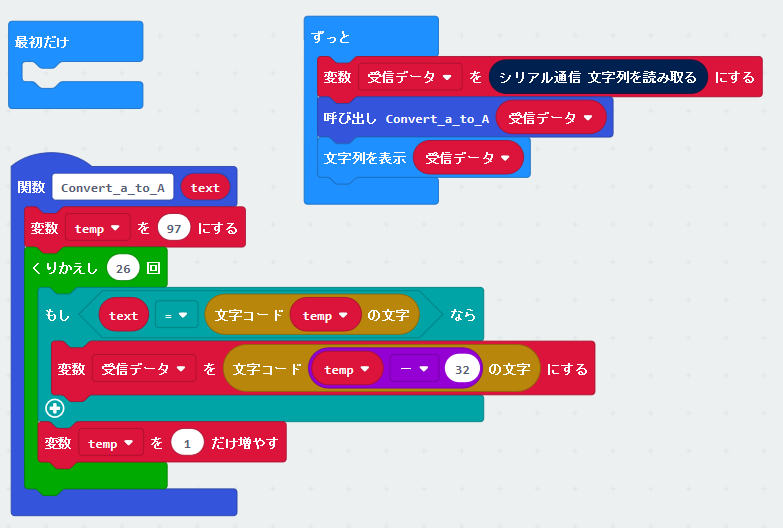
これで完成です!実際に是非、動きを確認してみてください。
最後に
小文字を大文字に変換するプログラム、如何でしたでしょうか?次からも色々なプログラムを書いていきますので、何か気になることがありましたら遠慮なくお問合せ下さい。