gcloud Shell 環境で Text-to-Speech を使ってみる
目次
はじめに
本記事ではGCPの Text-to-Speech 機能をとりあえず動かしてみる、その方法を説明します。
基本的なやり方は GCP公式のサイトに記載のクイックスタートの内容になります。
Text-to-Speechとは
ここに辿り着いた方が Text-to-Speech を知らないということはないと思いますが、その名の通り、テキストデータから音声データを作成することが出来るサービスとお考え下さい。
アプリケーションを設計した際に、音声での注意やセリフを入れたいといった際にこのText-to-Speechを使うことが可能です。これ、すごく便利じゃないですか。
実施方法
GCP のシェルコマンドが使用できる環境の構築
Windows 10 Home 上でGCPのシェルコマンド環境を構築する方法については以下をご参照ください。
Text-to-Speech のAPIの有効化
GCP の APIとサービスのページから Text-to-Speech のAPIを有効にしましょう。
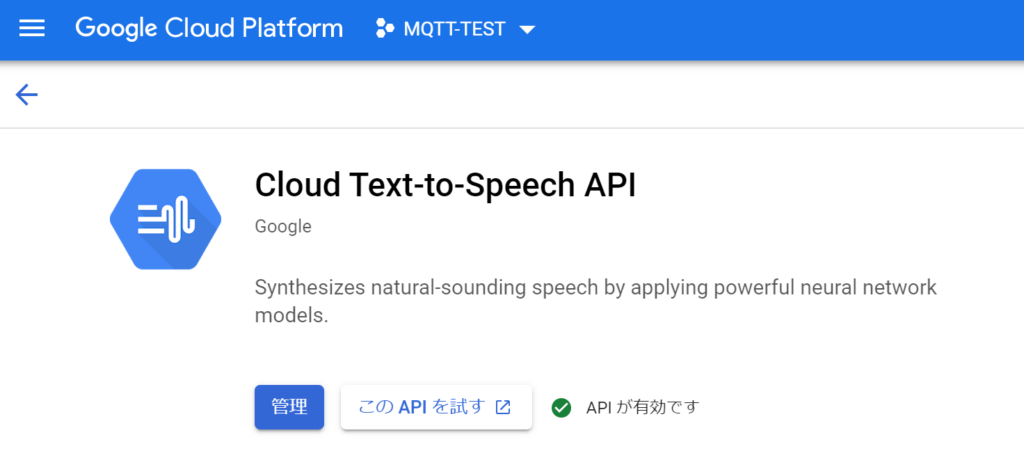
GCPのサービスアカウントの作成とJSONファイルのダウンロード
Text-to-Speechを使うために GCPのサービスアカウントの秘密鍵を含むJSONファイルが必要となります。以下のページを参照して秘密鍵を含んだJSONファイル(xxxxx.json) を用意してください。
JSONファイルの配置とPATHの指定
上記で作成したGCPのサービスアカウントのJSONファイルを gcloud のシェルが使用できる環境においてください。名前を service-account-file.json としています。
ここで以下のコマンドにて JSONファイルをGOOGLE_APPLICATION_CREDENTIALSの変数に指定してください。
export GOOGLE_APPLICATION_CREDENTIALS=/home/pi/service-account-file.json

スピーチさせたいメッセージを作成する
作成するのは
・何を話すか
・どの国のどの言語で
・男性の声か女性の声か
というところになります。設定ファイルは request.json というファイル名にします。
{
“input":{
“text":"この音声はGCPのテストです。"
},
“voice":{
“languageCode":"ja-JP",
“name":"ja-JP-Standard-A",
“ssmlGender":"FEMALE"
},
“audioConfig":{
“audioEncoding":"MP3″
}
}
text : 実際に話して内容を記載します。
languageCode : 音声コードを記載します。
name : 音声名を記載します。
languageCode/nameについては GCPの Text-to-Speechのリファレンスをご参照ください。
Text-to-Speechにテキストから音声への変換をお願いする
上記の設定が済んでいれば以下のコマンドで変換が可能です。
curl -X POST -H “Authorization: Bearer “$(gcloud auth application-default print-access-token) -H “Content-Type: application/json; charset=utf-8" -d @request.json https://texttospeech.googleapis.com/v1/text:synthesize
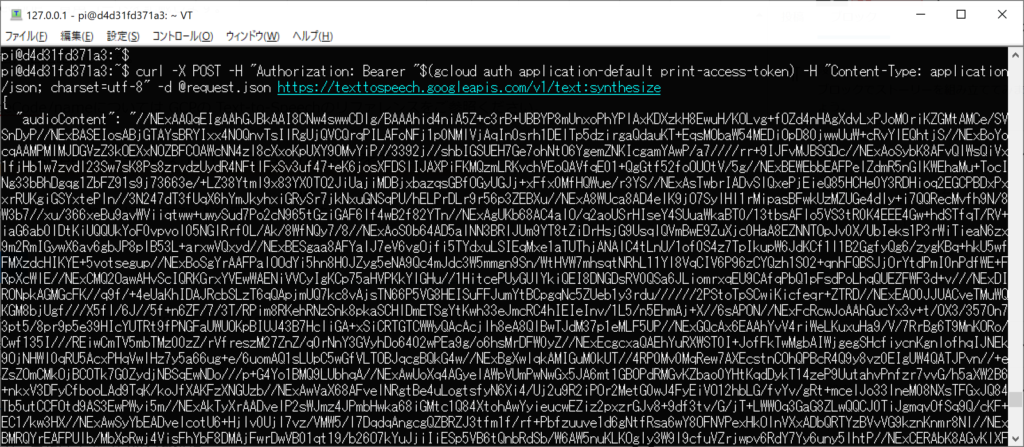
ここで audioContent の内容 (“" で囲われているよくわからない文字列)をコピーしてください。コピーが出来たらその内容を適当な audio.txt か何かのファイル名でその内容を保存してください。
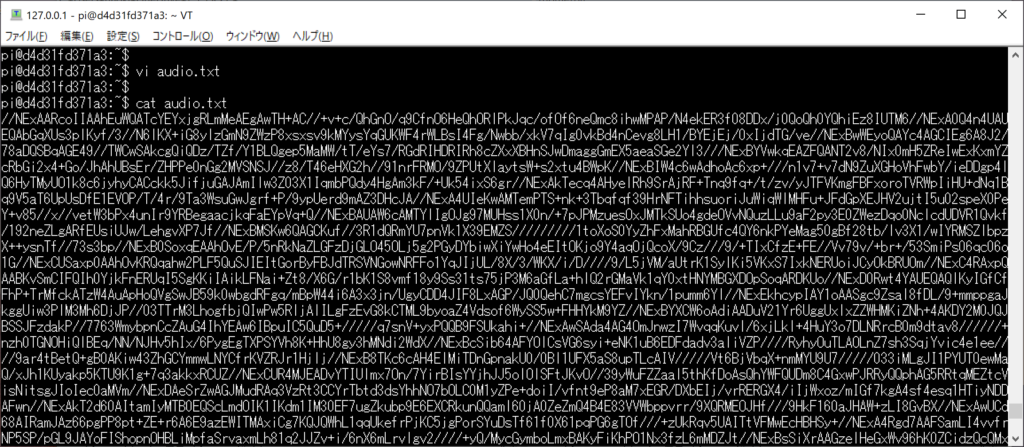
この文字列がBASE64という形式保存された音声データのようです。今度はこのファイルを以下のコマンドでMP3ファイルに変換します。
base64 audio.txt –decode > synthesized-audio.mp3

コマンドが通ったらmp3ファイルが出来ていますので、Windowsのデスクトップにファイルをもってきて再生してみましょう。
無事にテキストに設定したメッセージを読み上げてくれるかと思います。
さいごに
本記事では GCP の Text-to-Speechの基本的な使い方を説明しました。これだけで何かが作れるわけではありませんし、これだけではまだまだ使い勝手が悪いですね。
今後もっと私の方で勉強した内容を公開していきたいと思います。ではまた。